
सत्यं ब्रुयात् प्रियं ब्रुयान्नब्रुयात् सत्यमप्रियम् |
प्रियं च नानॄतं ब्रुयादेष धर्म: सनातन: ||
Speak truth. Speak what is pleasant to others.
Don't speak truth that is unpleasant ("harmful").
Even if pleasant, don't speak what is false.
This is Dharma for all time.
(Manusmṛti 4.138)
This article was revised on 25th Aug, 2020.
Abstract: The issue of fairness in the digital world is critical given the speed of the information flows. We first illustrate this through the use of the Indic word swastika as the highly unsuitable “synonym” of Hakenkreuz (“hooked cross”) of the Nazis. Next, we discuss a common preprocessing step called “word embeddings” (or similar) in current Web-scale systems that can introduce serious biases, even before any specific analysis (with its own biases) is even begun. We discuss this problem in the context of discourse that affects Indic representations.
Introduction: As we increasingly become information-centric in our lives, issues of fair representation become central. There is widespread unhappiness that the digital media is unfair to this group or that. In this note, we discuss one aspect that needs closer attention as it seems likely that it affects specially those in the Indic world more adversely.
That the sacred word स्वस्तिक has been misused by Nazis is “common knowledge”. However, this common “understanding” erases history about how it actually happened. Note that Hitler used Hakenkruez (“hooked cross”) for his party symbol as it is close to a symbol used in the Christian communities he grew up with and this term is the only one used in his book Mein Kampf (1925) written in German. Also, note that in the legislation of 12 Mar 1933, and the Reichsflaggengesetz of 15 Sep 19351 that extended the protection to the Hakenkreuzfahne2 (“the banner or flag of the hooked cross”), there is no mention of swastika.
But once the enormity of Hitler’s policies became known by the late-1930’s3, a sacred symbol of Indic people (swastika) was misused as its translation, possibly to erase the connection between Hitler and the Christian faith. This happened, to a large extent, through the first complete English translation of Mein Kampf in 1939 by James Murphy, an erstwhile Irish priest. Post WWII, it became de rigueur to use the Indic word swastika instead of “hooked cross” to avoid self-incrimination by the elites in the West given the horror of Holocaust.

Let us do a simple search on this Indic word of concern स्वस्तिक (swastik) using Google’s Ngram viewer4 on all English books published till 2019: for each year, the y-axis gives the percentage of occurences of a selected word or a phrase5 out of the same in all the books published that same year). We also list alongside the Nazi term for their symbol Hakenkreuz (“hooked cross”) that the Nazis actually used. Note that an early peak for swastika (between 1900 to 1920) occurred due to “swastika's" being discovered in Europe (such as in Troy, and hence discussion in books on archeology and ancient history) as well as Indological and German Volkisch writings.
The "hooked cross" as a translation for Hakenkreuz is seen early but picks up weakly in English only from 1930's and almost disappears about mid-50's till only recently. Note that the German word Hakenkreuz does not appear in English documents for all practical purposes. If we just compare the usages of swastika vs nazi (see second graph), though swastika has a “secular” rise all through except for the big spurt during the period around WWII, it is surprising that it has clearly grown past even “nazi” in its usage after the 1980s. After the mid-80s, swastika becomes the dominant term to be associated with Nazis in the English writings.
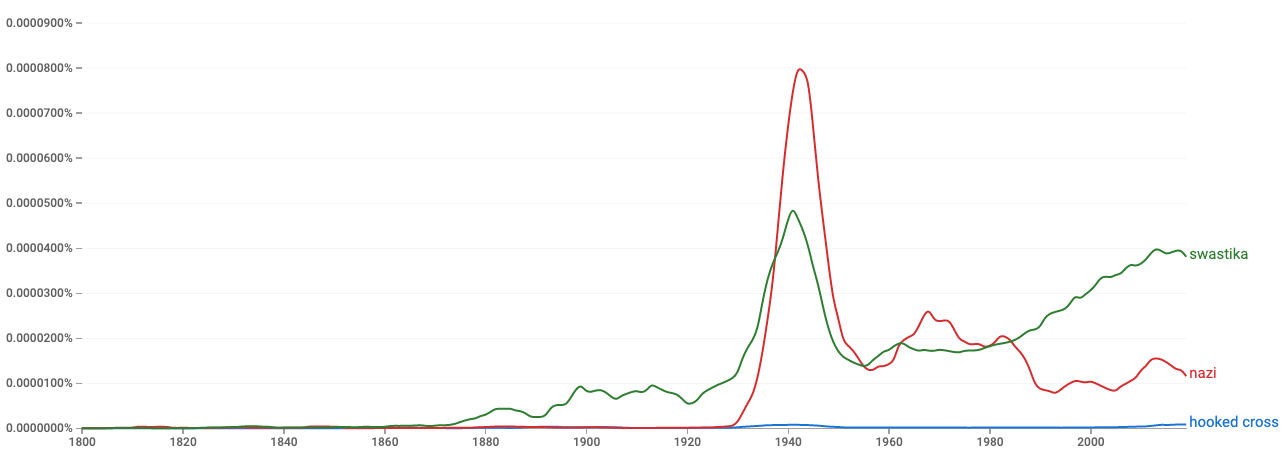
If only German books are to be considered(see third graph), the situation is somewhat different. Starting from just before WWII, the usage of the word Hakenkreuz picks up significantly.After 1930s, there is a trend of using the term swastika even in German writings instead of the German word Hakenkreuz used by the Nazis themselves, probably for the same reason given above.

Bias in Automated Analyses: The above is a simple example and analysis of bias in recent history where innocent bystanders (the Buddhists, Hindus, Jains) had their sacred symbol converted into a hateful symbol6. Such incidents will be more frequent with faster communications and increasing use of automated algorithms. The “demonization” of Sanskrit by some Western Indology academics is another example that we will discuss later on.
Bias or fairness in artificial intelligence (“AI”) or, more generally, in “automated” analyses – used widely in large companies (esp social media ones) such as Google, Facebook, Twitter – is a well known concern. For example, Google has a page on fairness7 (as a part of a crash course for developers of “AI” software) that discusses the following types of bias: reporting bias (selecting issues that seem interesting or special, rather than all issues that arise “objectively”), participation bias (data is not representative due to lack of participation from all), sampling bias (proper randomization is not used during data collection), group attribution bias (ascribing traits in a subsample to one’s own larger group if positive and to “competing” larger group if unfavourable), or implicit bias (personal experience guides the model evolution, such as stopping or continuing data collection and analysis till preformed opinions are vindicated).
However, it does not consider explicitly the possibility that “civilizational” biases can be lurking in many of these types of bias; they might not even be seen or registered as a bias as the thought system itself constrains the possibilities8. Maybe the early uses of swastika for Hakenkreuz was motivated, but later usage (say, after 1950’s) may just not be aware of the criminal targeting of the Indic symbol. Similarly, if an Indology researcher in US who is conversant only with Eurocentric research materials and familiar with or participates in current academic research in a strong “Western Universalist”9 framework, neither the researcher nor his/her peers may be aware that these is a bias as the only data available often is produced in that very same framework.
The word swastika now has unsavoury connections with Nazis; such unfortunate developments can become even more acute as Internet is now a global entity with propaganda campaigns as an important part of it, some of it happening through automated algorithms10. Improper automated analyses can result in restricting free and meaningful exchange of ideas that is critical to an aware citizenry. The connotations of a word (say, the brand name in business or commerce) or a person’s associations (say, in public life) are critical in how they fare over a period of time; those who lack the soft power or the hard power (for eg, political, monetary, military) to control them will eventually lose in an information-driven system. At many levels (including at the individual level), there are many issues of fairness, as propaganda is now an arm of Internet.
Word Embeddings and Bias:To illustrate this phenomenon, we will take a careful look at only one aspect, namely how a preprocessing step called as “word embeddings” (in the AI “frontend”) can, in principle, affect (and may be affecting) automatic analyses that is being carried out by large companies such as Google, Facebook and Twitter. Note that the later domain-specific processing11 may also have many biases as discussed before, but this preprocessing can cast a shadow on all the subsequent phases. Note that analyses of these later phases may be examined carefully and one may not discover any bias in some cases!
A word embedding is similar to the set of associations or connotations some word has that we just discussed; the new aspect is that they have a mathematical representation that can stand for the word. Embeddings are a way of representing information (can be concepts, names, geographies, relationships, etc) so that “nearby” or similar entities are also considered, as part of some analysis, without too much extra effort. For example, if one were to search for “best aeroplane” on Google, the very first result is about “aircraft”. It is obvious that synonyms or other mechanisms are used so that search becomes more meaningful12. Such synonyms can be given explicitly to the search algorithm (earlier search engines), or maybe that aspect could also be somehow “automated” (current designs).
For the first approach, due to gradations in meaning and the synonyms selected, search results may be surprising sometimes. There is thus a need for carefully choosing search key words, and there is also a whole industry on “search engine optimization” that advises on what words to use for high visibility on the web. Furthermore, a simple search based on a key word such as “criminal” may or may not not pick all the relevant articles; “criminal” may be connected with the word “murderer”, though they are somewhat different semantically. Such words are best considered as “close” but not identical. Unfortunately, this can also result in biased results due to human bias in the synonyms explicitly given. Sometime in the recent past (c. 2016), a Google search of ‘top criminals’ listed PM Modi as one of them13 . The bias aspect thus can get amplified, though the actual intention is to make search user friendly.
The second approach is based on what is termed as “word embeddings”: essentially, related words that are “close” in a linguistic sense are computed so that they are also close in a “mathematical” sense so that search algorithms can work on a more abstract problem where all close synonyms are also considered in the context of some problem (such as search). Thus when a search term is given not only are the words in the search term used but also words that are close, if not synonyms.
To make it more concrete, let us say, for simplicity, there are 3 important aspects on which we can rate the prime ministers of our country. One could be the importance placed on foreign affairs, one on sensitivity to Indic concerns and one on how much govt. control on the economy. Let us, again for simplicity, assign 1 or 0 only as the ratings. The first PM (Nehru) might have a rating (1,0,1) while the current PM (Modi) may have a rating (1,1,0), with a “distance” of 2 (as the 2nd and 3rd aspects are opposite). If we assign (1,0,1) for Indira Gandhi, then she has a distance of zero with Nehru but 2 with Modi. Thus we can cluster PMs based on their ratings; Nehru and Indira Gandhi are in one cluster and Modi in another. Suppose, instead of only 3 aspects, we have thousands or even millions of them. This is quite meaningful in many domains; consider Flipkart or Amazon with their huge product profiles.
Or the types or subject matter of songs or books. Working with millions of aspects is difficult even for a computer system; we need to find a more condensed representation (say, not more than a few hundreds), so that similar products get clustered together; when a search happens the clustered products can all be considered and the most “hot” among them can be returned to the user. An embedding can be thought of achieving this property.
Note that due to such embeddings, interesting relationships, some very desirable and some not so desirable or expected, also can be learnt; these result from the “distances” between the embeddings. These are similar to analogies that one learns in school: if A is related to B, what is D given C? Thus if “man : king :: woman : x”, word embeddings can reveal that x is “queen”. For a more involved example, an influential technical paper14 on embeddings from Google (2013) reports that, on a certain corpus, the embedding of “Russia” if added, in a mathematical sense, to the embedding of “river” is close to the embedding of “Volga River”: this happens as the corpus reinforces these connections (likely that they occur in close proximity multiple times in the text). Similarly, the embedding (“Germany”) + embedding (“capital”) is close to embedding (“Berlin”): “This compositionality suggests that a non-obvious degree of language understanding can be obtained by using basic mathematical operations on the word [embeddings].”
An unexpected or even undesirable relationship can also result due to the data used with all its various biases as given before (for example, due to “reporting” or “participation” bias). For example, due to embeddings discovered, a receptionist in US is much closer to softball than football due to female associations with both receptionist and softball.
Another interesting example is the set of relationships deduced across major “ethnic” categories and jobs held: due to the striking success of Asians in US, the newspaper corpus (Google News) used is likely to have caused the word embedding to reinforce the stereotypes. For Hispanics, the related top 10 occupations discovered are “housekeeper, mason, artist, janitor, dancer, mechanic, photographer, baker, cashier, driver” whereas for Asians it is “professor, official, secretary, conductor, physicist, scientist, chemist, tailor, accountant, engineer”. Contrast this for Whites, where it is “smith, blacksmith, surveyor, sheriff, weaver, administrator, mason, statistician, clergy and photographer”. Clearly, current newspapers are colouring the results as Asians seem to be dominant in the hard sciences in the relationships deduced.
Remedies?: Debiasing is an approach that has been proposed15 by using “crowd-worker evaluation as well as standard benchmarks”: essentially, manually studying the embeddings discovered and applying a correction. Unfortunately, this debiasing step has not been attempted in the Indian context and Indian researchers are taking US/European models wholesale (while acknowledging the problem)16 . Such models may be debiased with respect to concerns obtaining there but not with other concerns. We discuss the implications of this later.
From an Indic perspective, an unfortunate example is the spurious relationship deduced between Nazis and Sanskrit given that academic (Indological or Left/Socialistic) writings often emphasize stray “interesting” connections and deduce toxic “truths”17 based on their ideological predispositions.18 Thus depending on the input corpus used, the word embeddings can be biased resulting again in “garbage in, garbage out” (GIGO). We now discuss this in more detail, given its ability to colour later phases and also due to privacy and other issues.
Problems with word embeddings for the Indic World: We can thus identify some major issues wrt word embeddings:
First, the word embeddings can be an important issue in the automated analysis for Indic issues as ALL later analyses are affected if they are derived and trained on an unsuitable corpus in the preprocessing step19 itself. However, since we have no control over how Google, Facebook or Twitter trains their word embeddings, we will have a toxic corpus problem if the corpus has sources like British colonial texts, news sources such as BBC, NYT, Washington Post etc that have substantial documented biases20 ; there is a similar problem with even recent entrants like Netflix in the entertainment space. Furthermore, note that Google funds WorldVision with their CSR funds21 , a clear indication that Indic issues are not of any concern22. The problem is acute as this word embedding step is also often applied across other unrelated problems, as better word embeddings are not easy to compute given the lack of suitable data.
Given that Orientalism23 , “Western Universalism”24 and other perspectives routinely dominate the corpus, the representation of the corpus for downstream processing might thus be vitiated at the beginning itself at the most basic ontological level. Note that this is not just an academic worry as the Indic universe has been at the receiving end from Abrahamic world views as well as from the “progressive” or “social justice” perspectives for the last many decades.25 For example, Pollock, a major academic anchor in Indology currently, believes that Sanskrit is inherently oppressive26 (and internalised as such by the Left in India) and he has argued that Nazi leaders were receptive to employing such oppression themselves as they believed in “Aryan” superiority. While this imputed thesis between Sanskrit and Nazis has really no basis in reality, Pollock and his students have been successful in pushing this thesis widely. Hence, any analysis using the recent corpus (for example, articles in NYT, Washington Post, …) that deals with Sanskrit in even a very peripheral way is likely to pick up some fallacious connections between Sanskrit and Nazi ideology.
Thus if the word embedding of “Sanskrit” is close to that of “Nazi” (or embeddings for words like “repressive”, “hierarchical”, …), ALL the downstream processing is likely to be vitiated. Or, it may be that the triad “Germany – nationalism – Nazi” can get mapped to something like “Hindu – nationalism – Sanskrit/RSS”, which is similar to the “famous” Pollock’s “recapitulation” thesis27 now applied to Indics!
In certain countries (such as US, Germany, Britain), certain issues are more critical (or more “equal”) than others due to legal and negative PR effects; for example, any connection with Nazis is to be denounced very strongly (esp after WWII)28 . Thus anyone espousing Sanskrit will be willy-nilly connected to Nazi materials directly or through comments in social media platforms by “naive” users who have internalized the equation Nazi=Sanskrit (say, by naive “Pollock” followers). The corpus essentially ensures that a swastika is taken to be the symbol of Nazis and thus to be banned29 without considering that it has been a sacred symbol of Indics for more than 2 millennia30. Furthermore, the Left and the Abrahamics in India use indiscriminately words like “Hitler”, “Fascist”, “Nazi” etc when discussing RSS and BJP. This also poisons corpus unless someone carefully removes this serious bias in the uncleansed data.
Similarly, the discourse on Indic systems gets sidetracked systematically and in a negative direction through the use of the complex issue of caste by the Abrahamics and Left as a uniquely and reprehensible feature of the Indic systems. Unfortunately31 , the native varṇa-jāti system was misconstrued into an inflexible "caste" system by the British/Europeans based on their own social regimentation prevailing in Europe/Americas since at least the 15th century with, for example, castas, mestizos, and mulattos in the Americas. Furthermore, the “one-drop” rule in US statutes and elsewhere all the way into the beginning of the 20th century made even a “drop” of black or Native American blood made them the inferior race; even Thomas Jefferson’s children through his mixed race concubine were born into slavery, with some of them having to “escape” to become free! There is still an ongoing project in many parts of the West where the varṇa-jāti system is to be declared as equivalent to racism with attendant stringent penalties (eg. attempted discussion/legislation in UK/EU parliaments or UN, or in the academia where Dalits are equated with blacks through the Afro-Dalit project). A very recent book on caste32 , written by a “social justice” activist, conflates varṇa-jāti system with both the Nazi racism, and also the racism suffered by the blacks in the US and in the current economic system obtaining in the US.
Similarly, participation bias can occur dues to linguistic “walls”. For example, Hindi and other regional newspapers often report news that is of concern to Indics that is routinely suppressed in English media unless it blows up somehow. Ghettos or walled gardens abound in Indian social spaces (English vs “vernacular”, Hindi vs “South”, Urdu vs rest, …) and across Indian languages as much of Telugu, Odiya, Kannada, etc. articles remain untranslated unless they get somehow accommodated as translations into English.
Changes in Meanings over Time: Also, the time dependency of word embedding is not typically captured due to gaps in research till now and it is only now (last 2-3 years) that it is being considered from a research perspective. For example, “amazon” meant a forest till the late 90’s and now it means an Internet market place. This is the case if time-varying word embeddings are computed33 : thus some concepts close to “amazon” in ’93 are “forest, jungle, bird”, in ’98 “distribution, paragraph, worldwide”, in ’00 “yahoo, e-commerce, ebay”, ’08 “kindle, publishers”, and in ’16 “content, netflix, cable”. Such time dependency is of concern as Indics have been able to present their perspective well, and publicly too, only in the last decade or so. Any positive portrayal of Indic concerns is thus likely to be small in the corpus. Furthermore, any study of recent writings (say, American newspapers) will reveal that they employ stock phrases34 such as “nationalist Hindu” used in a deprecatory way or employ negative keywords liberally like “riots, uppercaste, oppression” or use liberally words such as “authoritarian, anti-minority” for a leader like Modi.
Due to the increasing scrutiny of Internet accounts35 , newer neologisms such as “ROL, ROP, peaceful, 786” have gained currency in the Indic discourse. There is thus a “cat and mouse” game with Facebook and Twitter, etc as they can ban accounts or certain usages/names36 . Thus embeddings have to change with time but this requires understanding the discourse, which is unlikely if the corpus is static or Eurocentric.
The Problem of Cliques: Furthermore, in a toxic social media space prejudiced against, say, group A, while B does not suffer from it, members of B can without difficulty write uncomplimentary tracts against group A (for eg, British/Christian authors between 1800-1950 and Islamic authors from 1200-1700, and left intellectuals till recently). This is also true to some extent with minorities/SC/ST as they have some protections available legally in India. Some political/cultural formations (for eg, DMK, DK, “Periyarist” groups) seem to have complete freedom to hurl invectives. Any writings of members of A will thus be couched in a disguised language (“have to read between the lines”). So a corpus based analysis will obviously be problematic unless “deep semantics” of the disguised text is understood. Current linguistic analysis (whether “AI” or not) is however not up to the mark.
Note that research that does not use word embeddings is necessarily better. For example, in one study at IIT Kharagpur (2018)37 , tweets during disasters are subjected to an “automated” analysis for hate (“communal”) speech. To make such analysis more “general” (not being event-dependent is a stated goal of this work), they take tweets on floods in Nepal and Kashmir and during the Gurdaspur attack to train their analysis and use it to predict hate speech in a completely different context (terrorist attacks in Paris and in California). May be the Indian subcontinent context is irrelevant for this study (ie, wrt local concerns, “Indian” slang38 , swear/curse words even if English is used in the tweets)! This is admitted as such (lack of suitable Indian subcontinent specific data) but then the paper gives a reader the misleading impression of systematic violence against minorities in India. This is also due to the use of the word “communal” because of its specific semantic usage in India. It is not surprising that every example, except one, chosen in this study is about abuse directed at Muslims or Christians; it seems as though other communities are relatively safe from this! The datasets used seem tailored to find only some communities as being subjected to hate speech39 . In spite of such obvious biases in the basic methodology itself, further work has continued with a 2020 paper40 that uses a listing of 1290 examples of hate speech in Twitter with their counter response; the surprise here is that 630 examples of hate speech against Muslims are identified (either in the tweet or in the response) but only 9 of them for Hindus41 ! There seems to be serious case of bias operating here with the data sets being unrepresentative and it is surprising that peer review has not caught these glaring biases.
Internationally, the research on hate speech seems to have similar biases. For example, an early (2016) work42 has a small data set (24K) of hate speech from the perspective of a “British Asian” (meaning Muslim) mostly with no hate terms for other than white, Islamic or black. By definition, no hate is possible against Indics! It is likely the dataset released by these research groups43 are also used by other research groups , including in India, thus coloring the conclusions. Because of the systematic disadvantage faced by Indic scholars, there is already some advice44 on how to be below the radar to avoid getting blocked by algorithms or reviewers: “Beating the Ban: How Not to Get Ambushed on Social Media”45. Thus different notable individuals in the social media space (eg. MediaCrooks, Rajiv Malhotra, Madhu Kishwar, TrueIndology, RealityCheckIndia) can have different run ins with Facebook or Twitter depending on their level of advocacy, for example, for Sanskrit or other “touchy” topics46 . It may be possible to reverse engineer what is going on in these social media platforms by studying who has got into problems and with what types of, say, text tweets.
Privacy Issues: There is also a privacy or fairness issue as unhelpful embeddings may make someone close to an undesirable label47 and endanger reputation or even life of the person. This issue has been studied in fair classification as the issue of direct versus indirect discrimination. Direct discrimination involves using sensitive features directly such as gender or race but indirect discrimination involves “using correlates that are not inherently based on sensitive features but that, intentionally or unintentionally, lead to disproportionate treatment”48 . In one study49 in the medical area, given different distributions of sickness in white and black populations across various diseases, if blacks do not spend as much on treating diseases, then using “cost” incurred as a way of measuring sickness will make whites eligible for (expensive) care-coordination across doctors/hospitals (to ensure that critical cases get the “best” treatment), and thus “free-ride” on the medical system at the cost of blacks. Like cost here, biased embeddings can make the evaluation unfair in a systemic manner.
Given the issue of unfairness, there have been many technical proposals50 for remedy as well as proposals for regulation at the govt level. In the US, the Algorithmic Accountability Act 2019 has just been introduced (not yet an act) and it attempts to regulate large entities that use automated decision systems to conduct impact assessments wrt accuracy, fairness, bias, discrimination, privacy, and security, and correct them as necessary.
Second, the corpus available can be engineered by newer methods of censorship, given the technological milieu. One newer technique is the characterization of deprecated content as being generated from spam51 sites. Wikipedia lists Swarajya, a respected alternate news source that has a sympathetic but critical ear to Indic issues, as spam52 (see https://en.wikipedia.org/wiki/MediaWiki:Spam-blacklist accessed Jun 8, 2020); note that the whole website is blocked (other than swarajyamag.com/about-us which is specifically whitelisted in https://en.wikipedia.org/wiki/MediaWiki:Spam-whitelist accessed Jun 8, 2020). Here the wiki content moderator positions (“editorships”) seem to have been taken over by an anti-Indic clique53 . Note that not one article of Swarajya (a monthly that has been running for close more than 5 years) can be listed as a reference anywhere in Wikipedia; such a sweeping power to “quietly censor” content is unprecedented in scope. Essentially, it is not what you say but what category you fall into. OpIndia is another upcoming online news site that has been banned from Wikipedia. Wikipedia has banned or labelled as “yellow” other news sources based on internal reviews. As wikipedia is considered the first point of reference for “neutral news” in most parts of the world (a major exception being China), wikipedia has more online censorship power than most govt’s as of now as it is worldwide!
Another abuse of the Wiki system is that the clique can also run the equivalent of a “protection racket”. A recent account of this abuse in India has been described54 through a “sting” operation. Another similar technique is the emergence of supposedly neutral “fact-checkers”; depending on one’s ideological orientation, a corpus may select only those materials that is in the “approved” categories. While this is unexceptional if dubious untrusted sources are excluded, the reality is different with cliques emerging.
Third, due to the weak monetary and political power of the Indic community at the global level, significant intellectual space in India is occupied by outside interests, good examples being George Soros55 at an “individual” level and global Abrahamics at the organized level (usually through NGOs). Due to this phenomenon, considerable negative portrayal of Indic systems happens on a regular basis. With the ability to set the tone of discussion (usually in English, being the hyperdominant language), many such interests can blow up minor or fictitious events as representative of the regressive or other wise negative aspects of the Indic world; the same interests operate in the inverse mode when malfeasance happens amongst their favoured groups or communities. Again, the corpus can be seriously polluted with a continuous stream of “grandstanding” statements about the reprehensible nature of Indian society (implicitly or explicitly targeting Indics). When the true nature of the contested incident becomes clear, there is mostly silence: the strategy of “lie big and retract small”!
This is a successful strategy as cycle of the “outrage till caught, then lie low” can be repeated as the Indian state does not have the capacity to inflict any cost on the malcontents, and hence furthers the intended propaganda. The implications for any automated analysis without any serious effort to “debias” the corpus can be imagined. We already mentioned that Modi is returned as a “murderer” on a search, as the first major sustained (decade or more) campaign seems to be on the Gujarat riots. Any serious attempt to shine some light on the subject (like for eg. Madhu Kishwar’s book on the subject) becomes problematic for the truth seekers themselves. The recent Delhi riots is another example.
Conclusions: We have discussed how data-based analysis is vitiated due to some embedding issues. We have given some examples but certainly not exhausted all the other issues. What we need at the minimum are word embeddings that are suitable or seen as fair by a “neutral” party. How is this to be done? Maybe every citizen should be provided a way to find the cloud of associations for terms of interest56 . Given a citizen’s profile, the citizen should be able to interrogate the associations that result from the word embedding and maybe also be able to request changes.
This is similar to the issue of web searches returning defamatory content for a person. This may be related also to the “Forget” functionality in Europe’s GDPR57 privacy regulations and also to “mobility” across web providers so that one can access one’s own data (ownership). There is widespread interest in such related issues with senate hearings in US and parliament questions in India (esp regarding Twitter’s banning of certain accounts, “shadowing”, etc).
References:
[1] https://en.wikipedia.org/wiki/Nazi_Anti-Flag_Desecration_Law
[2] https://de.wikipedia.org/wiki/Reichsflaggengesetz
[3] Note that as late as 1938, the British PM signed a treaty with Hitler for “Peace with Honour”.
[4] https://books.google.com/ngrams. We give the results smoothed over 3 years. See the caveats about the data in the info page. Variants of spellings, breaking words (eg. Hakenkreuz into Haken kreuz) etc. were also considered for getting trustworthy results.
[5] The technical word is Ngram (occurrences of a phrase with 1 upto 5 words). This ratio can be thought of the importance of a phrase in print (or, loosely, in public discourse) in a specific year.
[6] Recently, Nikki Haley, an American politician of Indian extraction, visited India. A picture of hers at a Hindu temple in Delhi had the swastika symbol in the background. Reuters “twittered” that it had censored the photo that had the swastika. See https://www.dnaindia.com/india/report-reuters-shows-its-ignorance-by-removing-picture-of-nikki-haley-with-swastika-at-hindu-temple-2631306
[7] https://developers.google.com/machine-learning/crash-course/fairness/types-of-bias
[8] For eg, relative pitch vs absolute pitch in Indian vs Western music systems can prevent appreciation across these boundaries.
[9] Rajiv Malhotra, “Being Different,” HarperCollins, 2011
[10] Tiktok is an example of an “automated feed” that can in principle be captured, at a central level, to present motivated content; this is an issue as Tiktok, against Android policies, also has been capturing the device IDs (“MAC”). If location information is available (which is very likely), Tiktok can easily attempt something similar to what Cambridge Analytica set out to do. This is possible for Twitter and Facebook to some extent only as the user exercises more control.
[11] A widely used example in the “fairness” literature is the bail decisions in the US. A proprietary software ranks the subjects and it has been found that whites with more serious crimes more often get bail while blacks with less serious crimes often fail to get bail. Increasingly, health care, insurance, and credit scoring use automated metrics instead of human decisions; the biases inherent in the machine predictions are often simply not known. In India, bail decisions are not automated but subject to local pulls and pressures, with many anti-Indic overtones.
[12] Another example: if “Katwa killing” is searched for, Google also lists in the 3rd position “Kathua rape case – Wikipedia". Thus phonologically similar keywords also seem to be added by Google’s search engine; it could also be the result of the kind of unforeseen relationships that techniques like embeddings also surface.
[13] https://timesofindia.indiatimes.com/india/Google-lists-PM-Modi-in-top-criminals-gets-court-notice/articleshow/53292860.cms, Jul 20, 2016
[14] Mikolev, et al. “Distributed Representations of Words and Phrases and their Compositionality,“ NIPS Dec 2013. The dataset was from various news articles (from an internal Google dataset of 1B words); it discarded all words that occurred less than 5 times in the training data, with the final vocabulary size 692K. For the technical minded who want to understand details, a recent book by Tommaso Teofili, “Deep Learning for Search”, Manning, 2019 may be consulted.
[15] Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama, Adam Kalai, “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings,” https://arxiv.org/pdf/1607.06520, 2016
[16] AFAIK, there is still no paper that describes attempts in this direction.
[17] see K. Gopinath, “German Indology, Sanskrit and Nazi ideology,” WESTERN INDOLOGY& ITS QUEST FOR POWER ed. K.S. Kannan, 2017
[18] Due to lack of support for Indic studies in India (the Indian education being captured by anti-Indic forces – note that in the first 3 decades of the formative years of the Indian republic, education minsters were either Muslims or the Left; this is even more lopsided in states like Kerala), and the academic system’s need for “new results” for career advancement esp in US & Europe, any stray theory (such as Rāmakrishna being a paedophile pushed in US in the ’90s) can get prominence given the lack of a countervailing system of academic rigour. To survive in the US/Europe academic systems esp in the humanities area, publishing a book is critical; hence in any area of Indic studies, authors from the West predominate, colouring the perception of “innocent” readers
with their biases. Similarly, names such as “South Asia” to stand for the “Indian subcontinent” quickly become dominant in the academia due to the monetary and political power of US.
[19] For details, see Mikolev et al op. cit. where “word2vec” embeddings are discussed, or Teofili op. cit.
[20] For BBC see, Alasdair Pinkerton (Oct 2008). "A new kind of imperialism? The BBC, cold war broadcasting and the contested geopolitics of South Asia". Historical Journal of Film, Radio and Television 28 (4): 537–555. This is a peer-reviewed article that analyses BBC Indian coverage from independence through 2008; it concludes that BBC coverage of South Asian geopolitics and economics has had a pervasive Indophobic slant. For NYT, for a good summary, see https://en.wikipedia.org/wiki/Anti-Indian_sentiment#New_York_Times (accessed Jul 28, 2016).
[21] In 2011, Google’s CSR program in the US (the largest at that time) funded World Vision, which uses “atrocity literature” for conversion purposes in India.
[22] Similarly, the Facebook oversight board has a significantly large Islamic representation:
Karman (who was a senior leader of Yemeni Muslim Brotherhood-linked Al-Islah party), Jamal Greene (Law Prof, Columbia), Afia Asantewaa Asare-Kyei (a Ghana human rights lawyer and Program Manager at the Open Society Initiative (“Soros”) for West Africa), Evelyn Aswad (Arab-American Law Prof, Okla), ENDY BAYUNI (Indonesia), NIGHAT DAD (Pak), with only SUDHIR KRISHNASWAMY (NLSIU) from India. In spite of such lopsided representation, Mark Zuckerberg (Facebook head) has described the Board thus: “You can imagine some sort of structure, almost like a Supreme Court, that is made up of independent folks who don’t work for Facebook, who ultimately make the final judgment call on what should be acceptable speech in a community that reflects the social norms and values of people all around the world”. The whole world is the playing ground!
Twitter’s chief, when he recently visited India (2018), seems to have been stage managed by “social justice” activists to hold a poster bearing the slogan “Smash Brahminical Patriarchy”. The patriarchy of the Abrahamics is almost never called out, even when heinous crimes of their priestly class happen semi-regularly, with most of the press looking the other way.
[23] Said, Edward W., "Orientalism," Knopf Doubleday, 1979
[24] Rajiv Malhotra, “Being Different,” HarperCollins, 2011
[25] given that Indics are only about 1/9th worldwide with a poorer monetary and soft power status.
[26] See K Gopinath, op. cit.
[27] Pollock, Sheldon. 1993. “Deep Orientalism? Notes on Sanskrit and Power Beyond the Raj.” In Carol A. Breckenridge and Peter van der Veer, eds., Orientalism and the Postcolonial Predicament: Perspectives on South Asia, 76–133. Philadelphia: University of Pennsylvania Press (South Asia seminar series. New Cultural Studies. Papers presented at the 44th Annual South Asia Seminar held at the University of Pennsylvania, 1988/1989).
[28] By setting hate speech bar for “nazi” talk lower than for others (in the AI “backend”) due to the terrible Holocaust and Jewish soft power in US. Note however that this bar does not apply for
critical issues/resources in the larger national context; an excellent historical example is the wholesale induction of Nazi scientists in the space program in the US just after WWII; something similar happened in USSR also.
[29] being considered in US as of now
[30] See K. Gopinath op. cit.
[31] This and the next 2 sentences are taken verbatim from K. Gopinath, op. cit. which has more details on this complex issue in the context of Pollock’s writings.
[32] For a critical opinion, see Ramesh Rao, “Trotting Out the Caste Horse and Flaying It”, https://medium.com/@rameshrao_89399/trotting-out-the-caste-horse-and-flaying-it-1e0a243513a7
[33] Zijun Yao et al., “Dynamic Word Embeddings for Evolving Semantic Discovery” (International Conference on Web Search and Data Mining, 2018), https://arxiv.org/abs/1703.00607.
[34] it looks as though there is a required “writing style” across all these organizations! Or they are referring to older writings from their own “stables” and internalizing them.
[35] see Rakesh Krishnan Simha, http://indiafacts.org/beating-the-ban-how-not-to-get-ambushed-on-social-media/, 07-05-2020
[36] There is also “mass reporting” against certain targets by organized groups; we do not discuss such dynamics here as it happens at a meta level “higher” than the text level.
[37] Koustav Rudra , Ashish Sharma, Niloy Ganguly, and Saptarshi Ghosh, “Characterizing and Countering Communal Microblogs During Disaster Event,” IEEE TRANSACTIONS ON COMPUTATIONAL SOCIAL SYSTEMS, VOL. 5, NO. 2, JUNE 2018. Tables X and XI are good examples of the lopsided bias in the article.
[38] A recent twitter comment that illustrates this issue broadly: “More than 80% Tamils in Tamil Nadu are Hindus and most of them are devout Hindus. Sadly Pakistanis & porkis hijack the silent majority both in social media and in TV channels. I am a Tamilian, In my whole life I haven't seen a Tamil worshipping Ravana in real life.” Note also the use of a SM “slang” to attempt to escape from key-word based “targeting” either by algorithms or by cliques.
[39] As one example of the problematic use of databases, the paper mentions that it also incorporates “hate” terms from www.hatebase.org, a dataset that however has no serious understanding of the Indian context. There are no hate words listed against “India”, “Gujarati”, “Malayali”, “Marathi”, “Naga”, “Punjabi”, “Sindhi”, “Telugu”, considers “Bengali” or “Bihari” as a hate word, but lists 24 for Rohingyas, 130 for Islam, seven for Tamil (but all from Sri Lanka related sources). It also uses a website curated in the West (www.noswearing.com) but it does not have the two most obvious curse words in Hindi (m* and c*) or its disguised versions. Furthermore, they use terms in a standard lexicon of religious terms http://www.translationdirectory.com/glossaries/ but it is “Forbidden” for access as of now. Note that none of them have any serious relevance in the Indian subcontinent context. While the paper mentions that a lexicon dataset is available at http://www. cnergres.iitkgp.ac.in/disasterCommunal/data set.html, it is not accessible as of now.
[40] Binny Mathew et al. “Interaction Dynamics between Hate and Counter Users on Twitter,” CoDs-COMAD, 2020. Accessed 9 Aug 2020.
[41] Even here, of the 9 instances of hate speech against Hindus, there only 2 distinct instances (with one having 3 repeats) with 4 of them occurring in the counter response. There are far more instances for Jews, thus clearly showing that the database is unsuitable for analysis in the Indian context.
[42] Zeerak Waseem & Dirk Hovy, “Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter,” 2016
[43] There are atleast 7 such papers between 2017-2019 that used Waseem’s data. This data has a citation count of 200+ (ie mostly cited but not used in the research itself).
[44] For example, “unless your name is Sunil Kumar or John Smith, use only your first name. If you have a relatively uncommon last name, don’t present your full name online.”
[45] Rakesh Krishnan Simha, http://indiafacts.org/beating-the-ban-how-not-to-get-ambushed-on-social-media/, 07-05-2020. If a stray comment is classified as a problem, then a later simple tweet
may also be classified as a problem if the author’s information gets embedded in the word embeddings. It can thus swamp any positive work.
[46] For example, RealityCheckIndia, AFAIK, has not been troubled by Twitter though he is a serious and consistent commentator on Dravidian politics. MediaCrooks has had multiple bans but this is likely due to organized gangs reporting his twitter accounts.
[47] For example, labels that someone is interested in some devious activity (eg. drugs, pornography) due to name or circumstantial similarities, can result in a “flood” of inappropriate advertisements.
[48] Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama, Adam Kalai, “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings,” https://arxiv.org/pdf/1607.06520
[49] Ziad Obermeyer UC Berkeley, Sendhil Mullainathan, “Dissecting Racial Bias in an Algorithm that Guides Health Decisions for 70 Million People,” FAT2019.
[50] ALEXANDRA CHOULDECHOVA AND AARON ROTH, “A Snapshot of the Frontiers of Fairness
in Machine Learning,” CACM May 2020.
[51] Spam is “unsolicited” information, ie. very low quality information.
[52] “The spam blacklist is a control mechanism that prevents an external link from being added to an English Wikipedia page when the URL matches one listed at MediaWiki:Spam-blacklist." https://en.wikipedia.org/wiki/Wikipedia:Spam_blacklist
[53] Usually, the “left” intelligentsia and the Abrahamics working together. While this might seem surprising, there is enough evidence. For a longer treatment of the issues, see K. Gopinath, “German Indology, Sanskrit and Nazi ideology,” WESTERN INDOLOGY& ITS QUEST FOR POWER
ed. K.S. Kannan, 2017 (esp. from p. 44). We give 2 examples here: Modi’s visit to US, when he was the CM of Gujarat, was thwarted by a collaboration between evangelical Christian Right in the US, the Indian (expat) Left and the Islamic interests even when not a single FIR was filed against him (and till today not filed) (NYT, Janmohamed 2013). When Swami Laxmanananda Saraswati in Orissa was killed, it was again a surprising collaboration between Maoists and evangelical Christians, just as the most recent (May 2020) killings of Sādhu-s also in Palghar (for a detailed report on the Orissa case, see Brannon Parker, “ORISSA in the CROSSFIRE: Kandhamal Burning,” Nov’09.) The recent Delhi riots (Dec’19-Mar’20) is another example (see OpIndia’s recent report “Delhi Anti-Hindu Riots 2020, The Macabre Dance of Violence Since December 2019”); see also Madhu Kishwar, “Modi Muslims and Media: Voices from Narendra Modi’s Gujarat,” 2014. The Kathua killing in Jammu and Palghar killings do not still have a book level treatment; there are strong indications that “left” intelligentsia and the Abrahamics have worked together in these two cases also.
[54] See https://twitter.com/Soumyadipta/status/1235098631738281984 for the expose. Since this link may get removed, a summary is given here: First, Wikipedia (in India at least) is a big business opportunity, hence tightly controlled. It takes years for a Wiki editor to climb up the hierarchy with Wikipedia giving badges, stars etc in recognition of good work. However, promotions are not possible unless there is tacit support from the “clique”. To climb up the hierarchy on Wikipedia, any edits made needs to stick. Due to the automated algorithms, if edits get reversed or deleted frequently then Wikipedia algorithms mark the editor as not skillful (see the original article on this method: B. Thomas Adler and Luca de Alfaro, “A Content-Driven Reputation System for the Wikipedia,” WWW’07.). This system has now been gamed by the clique: if they want someone out, they will reverse edits systematically. It is said that the top (Indian) editors make about 5L pm as “consultants" with “support” agencies making about 3L pm; however Wikipedia is not involved as all of this is projected as IT related consultation of an Ad agency or a PR agency. The (Indian) editors ensure that all money is properly accounted for and electronically transferred with tax being paid on the income as consultants.
[55] https://economictimes.indiatimes.com/markets/stocks/news/george-soros-says-modi-creating-a-hindu-nationalist-state/articleshow/73589314.cms: “Nationalism, far from being reversed, made further headway.” The biggest and “most frightening setback,” [Soros] said “came in India where a democratically elected Narendra Modi is creating a Hindu nationalist state, imposing punitive measures on Kashmir, a semi-autonomous Muslim region, and threatening to deprive millions of Muslims of their citizenship.”
[56] For example, the swastika (instead of the cross) has unfortunate associations with the Nazis due to improper translation. This needs to be corrected.
[57] General Data Protection Regulation